Chapter 8 - Forecasting (Dự báo)
Tổng quan (Overview)
Forecasting (Dự báo) là quá trình dự đoán các sự kiện trong tương lai, đặc biệt là Demand (nhu cầu) của khách hàng đối với sản phẩm hoặc dịch vụ. Đây là nền tảng cho hầu hết mọi quyết định trong Operations Management vì nó ảnh hưởng trực tiếp đến Inventory Management, Capacity Planning, Scheduling, và Supply Chain Management. Không có doanh nghiệp nào có thể hoạt động hiệu quả mà không có dự báo — dù chính xác 100% là điều không thể, nhưng một dự báo tốt sẽ giảm thiểu rủi ro và tối ưu hóa nguồn lực.
Trong chương này, chúng ta sẽ tìm hiểu các Demand Patterns (mẫu nhu cầu), các phương pháp dự báo từ đơn giản đến phức tạp, cách đo lường sai số dự báo (Forecast Error), và cách áp dụng Big Data vào dự báo hiện đại. Mỗi phương pháp có ưu nhược điểm riêng và phù hợp với các tình huống khác nhau — điều quan trọng là hiểu khi nào nên dùng phương pháp nào.
Dự báo không chỉ là công việc của bộ phận kinh doanh mà là trách nhiệm chung của toàn tổ chức. Từ Marketing cung cấp thông tin thị trường, Finance cần dự báo doanh thu, đến Operations cần biết sản xuất bao nhiêu — tất cả đều phụ thuộc vào chất lượng dự báo.
Managing Demand (Quản lý nhu cầu)
Định nghĩa (Definition)
Managing Demand là quá trình hiểu và tác động đến nhu cầu của khách hàng, bao gồm việc nhận diện các Demand Patterns và áp dụng các chiến lược để cân bằng cung-cầu.
Giải thích chi tiết (Detailed Explanation)
Demand Patterns (Các mẫu nhu cầu)
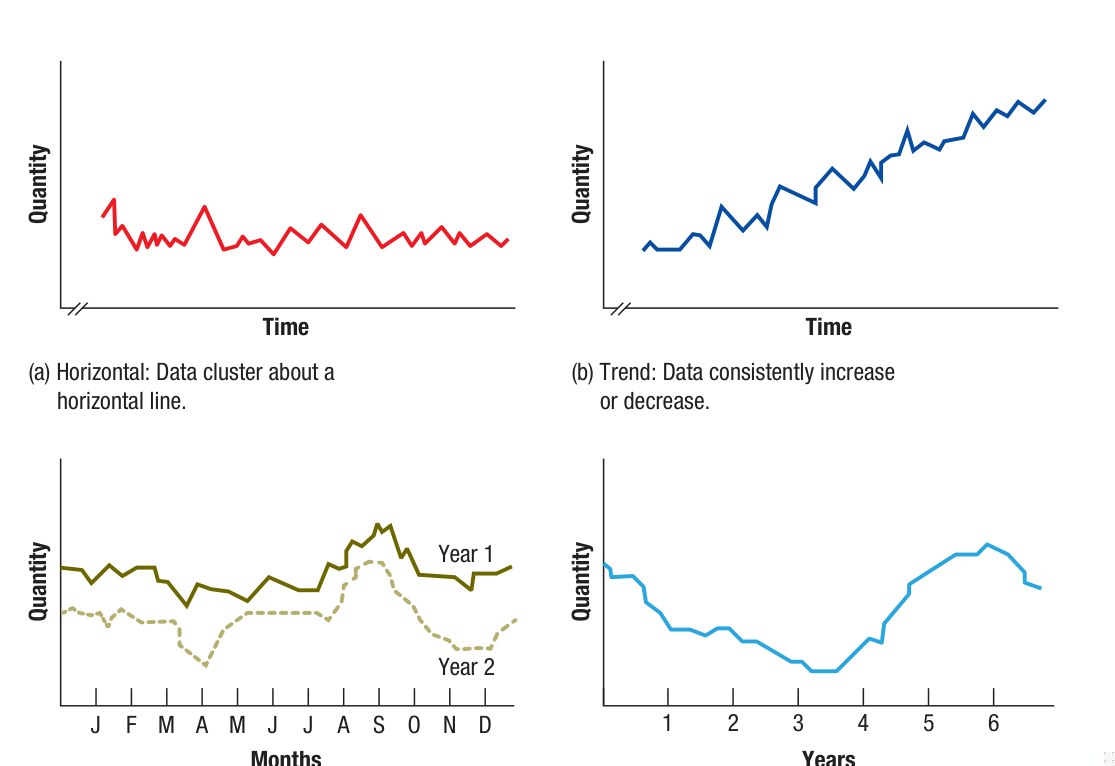
Figure 8.1: Các mẫu nhu cầu (Demand Patterns) — Trend, Seasonal, Cyclical, và Random Variation
Nhu cầu hiếm khi ổn định hoàn toàn. Có 5 thành phần cơ bản của Demand Patterns:
-
Trend (Xu hướng): Sự tăng hoặc giảm dài hạn trong nhu cầu. Ví dụ: nhu cầu xe điện Tesla tăng liên tục qua các năm do xu hướng xanh hóa giao thông.
-
Seasonal Pattern (Mẫu mùa vụ): Sự lặp lại có thể dự đoán được theo chu kỳ ngắn (tuần, tháng, quý). Ví dụ: nhu cầu bia tăng mạnh vào mùa hè ở Việt Nam, áo ấm bán chạy vào mùa đông.
-
Cyclical Pattern (Mẫu chu kỳ): Sự dao động dài hạn hơn mùa vụ, thường liên quan đến Business Cycle (chu kỳ kinh tế). Ví dụ: nhu cầu bất động sản tăng mạnh trong giai đoạn kinh tế phát triển, giảm khi suy thoái.
-
Random Variation (Biến động ngẫu nhiên): Những thay đổi không thể dự đoán, không theo mẫu nào. Ví dụ: một bài đăng viral trên TikTok bất ngờ làm tăng nhu cầu một sản phẩm.
-
Level (Mức cơ bản): Nhu cầu trung bình cơ sở khi loại bỏ tất cả các yếu tố trên.
Demand Management Options (Các lựa chọn quản lý nhu cầu)
Thay vì chỉ bị động phản ứng với nhu cầu, doanh nghiệp có thể chủ động tác động:
- Complementary Products: Sản xuất sản phẩm bổ sung để cân bằng mùa vụ. Ví dụ: một nhà máy sản xuất kem (bán chạy mùa hè) có thể thêm sản phẩm chocolate nóng (bán chạy mùa đông).
- Promotional Pricing: Giảm giá trong mùa thấp điểm để kích cầu. Ví dụ: Grab giảm giá chuyến xe vào giờ trưa khi ít khách.
- Backlog / Backorder: Nhận đơn hàng và giao sau. Phổ biến trong ngành sản xuất theo đơn (Make-to-Order).
- Reservation Systems: Hệ thống đặt chỗ trước (nhà hàng, khách sạn, hãng bay).
- Revenue Management: Định giá linh hoạt theo nhu cầu — Vietnam Airlines bán vé giá cao hơn gần ngày bay.
Ví dụ thực tế (Real-world Example)
Chuỗi siêu thị Bách Hóa Xanh phải dự báo nhu cầu hàng ngày cho hàng nghìn SKU. Nhu cầu rau xanh tăng trước Tết (Seasonal Pattern), xu hướng mua thực phẩm organic tăng qua các năm (Trend), và đợt nắng nóng bất ngờ làm tăng nhu cầu nước giải khát (Random Variation).
Liên kết (Related Concepts)
Key Decisions on Making Forecasts (Các quyết định quan trọng khi dự báo)
Định nghĩa (Definition)
Trước khi bắt đầu dự báo, nhà quản lý cần trả lời 5 câu hỏi quan trọng:
Giải thích chi tiết (Detailed Explanation)
-
Dự báo cái gì? (What to forecast?)
- Mức độ tổng hợp (Aggregation Level): Dự báo tổng doanh thu hay từng SKU? Thường bắt đầu từ tổng rồi phân bổ xuống.
- Đơn vị đo: doanh thu (VND), số lượng (units), giờ lao động?
-
Dự báo cho khoảng thời gian nào? (Time horizon?)
- Short-range Forecast: 1-3 tháng, dùng cho Scheduling và Inventory Management
- Medium-range Forecast: 3 tháng - 2 năm, dùng cho S&OP - Sales and Operations Planning
- Long-range Forecast: >2 năm, dùng cho Capacity Planning và Facility Location
-
Dùng phương pháp gì? (Which forecasting method?)
- Judgment Methods (Phương pháp định tính)
- Causal Methods (Phương pháp nhân quả)
- Time-Series Methods (Phương pháp chuỗi thời gian)
-
Dữ liệu nào có sẵn? (Data availability?)
- Sản phẩm mới: ít data → dùng Judgment Methods
- Sản phẩm hiện tại: nhiều data lịch sử → dùng Time-Series Methods
-
Độ chính xác cần thiết? (Required accuracy?)
- Chi phí của sai số dự báo so với chi phí cải thiện dự báo
Liên kết (Related Concepts)
Forecast Error (Sai số dự báo)
Định nghĩa (Definition)
Forecast Error là sự khác biệt giữa giá trị thực tế (Actual Demand) và giá trị dự báo (Forecast). Công thức cơ bản: E_t = D_t - F_t (trong đó D_t là nhu cầu thực, F_t là dự báo tại thời điểm t).
Giải thích chi tiết (Detailed Explanation)
Có 4 thước đo sai số dự báo chính:
1. CFE - Cumulative Sum of Forecast Errors (Tổng tích lũy sai số)
- Đo lường thiên lệch (bias) của dự báo
- CFE > 0: dự báo thường thấp hơn thực tế (under-forecasting)
- CFE < 0: dự báo thường cao hơn thực tế (over-forecasting)
- CFE ≈ 0: dự báo không bị thiên lệch (nhưng có thể vẫn sai nhiều!)
Ví dụ: Nếu 4 tháng liên tiếp bạn dự báo bán 100 nhưng thực tế bán 110, 90, 120, 95 thì CFE = 10 + (-10) + 20 + (-5) = 15 → dự báo hơi thấp.
2. MAD - Mean Absolute Deviation (Độ lệch tuyệt đối trung bình)
- Đo lường mức độ phân tán trung bình của sai số
- Luôn dương (vì lấy trị tuyệt đối)
- Dễ hiểu: “trung bình mỗi kỳ, dự báo sai bao nhiêu đơn vị?”
Ví dụ: Với sai số |10|, |-10|, |20|, |-5| → MAD = (10+10+20+5)/4 = 11.25 đơn vị
3. MAPE - Mean Absolute Percent Error (Sai số phần trăm tuyệt đối trung bình)
- Đo sai số theo phần trăm → dễ so sánh giữa các sản phẩm khác nhau
- Sản phẩm bán 10.000 đơn vị sai 100 (1%) khác với sản phẩm bán 200 đơn vị sai 100 (50%)
Ví dụ: Với D = 110, 90, 120, 95 và F = 100 cho mỗi kỳ: MAPE = [(10/110 + 10/90 + 20/120 + 5/95) × 100] / 4 ≈ 10.0%
4. MSE - Mean Squared Error (Sai số bình phương trung bình)
- Phạt nặng các sai số lớn (vì bình phương)
- MSE = (100 + 100 + 400 + 25)/4 = 156.25
Ví dụ thực tế (Real-world Example)
Một cửa hàng Highlands Coffee dự báo bán 200 ly cà phê/ngày. Thực tế bán 230 ly → thiếu nguyên liệu, khách phải chờ. Nếu dự báo 250 nhưng bán 200 → thừa nguyên liệu, lãng phí sữa tươi. MAD giúp biết trung bình sai bao nhiêu, MAPE cho biết sai bao nhiêu phần trăm, CFE cho biết có thiên lệch hay không.
Liên kết (Related Concepts)
Judgment Methods (Phương pháp định tính)
Định nghĩa (Definition)
Judgment Methods (còn gọi là Qualitative Methods) là các phương pháp dự báo dựa trên ý kiến, kinh nghiệm và trực giác của con người thay vì dữ liệu số.
Giải thích chi tiết (Detailed Explanation)
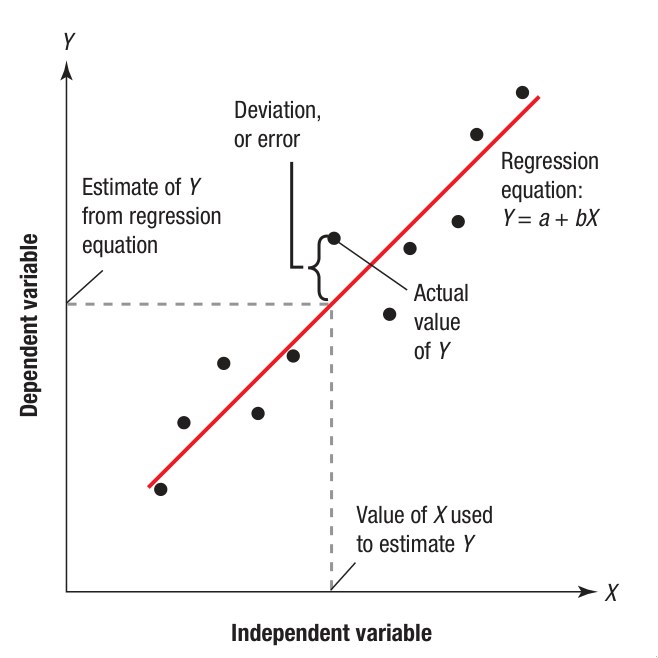
Figure 8.3: Tổng quan các phương pháp dự báo — Judgment, Causal, và Time-Series
Sử dụng khi: sản phẩm mới, không có dữ liệu lịch sử, hoặc môi trường thay đổi nhanh.
-
Sales Force Estimates (Dự báo từ đội ngũ bán hàng)
- Nhân viên bán hàng gần khách nhất → hiểu nhu cầu tốt
- Nhược điểm: có thể thiên lệch (dự báo thấp để dễ đạt target)
- Ví dụ: Đội sales Vinamilk báo cáo rằng đại lý ở miền Tây đang tăng đặt hàng sữa chua
-
Executive Opinion (Ý kiến ban lãnh đạo)
- Lãnh đạo cấp cao dùng kinh nghiệm và tầm nhìn chiến lược
- Kết hợp thông tin từ nhiều phòng ban
- Nhược điểm: bị ảnh hưởng bởi người có quyền lực nhất trong phòng
-
Market Research (Nghiên cứu thị trường)
- Khảo sát, phỏng vấn, nhóm tập trung (Focus Group)
- Tốn kém nhưng cần thiết cho sản phẩm mới
- Ví dụ: VinFast khảo sát ý kiến khách hàng Mỹ trước khi ra mắt VF8
-
Delphi Method (Phương pháp Delphi)
- Nhóm chuyên gia trả lời bảng hỏi ẩn danh, qua nhiều vòng
- Vòng 1: mỗi người đưa ra dự báo độc lập
- Vòng 2: xem kết quả tổng hợp, điều chỉnh lại
- Lặp lại đến khi hội tụ
- Ưu điểm: tránh hiệu ứng “bandwagon” (a dua theo đám đông)
- Ví dụ: Dự báo nhu cầu chip bán dẫn cho Việt Nam 2030
Ví dụ thực tế (Real-world Example)
Khi Apple ra mắt iPhone đời đầu (2007), không có dữ liệu lịch sử về smartphone. Họ dùng kết hợp Executive Opinion (Steve Jobs), Market Research (khảo sát người dùng iPod), và Sales Force Estimates để dự báo nhu cầu.
Liên kết (Related Concepts)
- Collaborative Planning, Forecasting, and Replenishment (CPFR)
- Demand Management
- New Product Development
Causal Methods: Linear Regression (Phương pháp nhân quả: Hồi quy tuyến tính)
Định nghĩa (Definition)
Causal Methods giả định rằng nhu cầu có mối quan hệ nhân quả với một hoặc nhiều biến độc lập. Linear Regression tìm đường thẳng tốt nhất biểu diễn mối quan hệ này.
Giải thích chi tiết (Detailed Explanation)
Figure 8.7: Hồi quy tuyến tính (Linear Regression) — đường thẳng tốt nhất mô tả mối quan hệ nhân quả
Mô hình hồi quy tuyến tính:
Trong đó:
- = giá trị dự báo của Dependent Variable (biến phụ thuộc = nhu cầu)
- = Independent Variable (biến độc lập = yếu tố ảnh hưởng)
- = Intercept (hệ số chặn — giá trị y khi x = 0)
- = Slope (hệ số góc — nhu cầu thay đổi bao nhiêu khi x tăng 1 đơn vị)
Công thức tính b và a:
Correlation Coefficient (Hệ số tương quan r):
- r gần +1: mối quan hệ tuyến tính dương mạnh
- r gần -1: mối quan hệ tuyến tính âm mạnh
- r gần 0: không có mối quan hệ tuyến tính
Coefficient of Determination ():
- Cho biết % biến thiên của y được giải thích bởi x
- Ví dụ: = 0.85 → 85% sự thay đổi nhu cầu được giải thích bởi biến x
Ví dụ thực tế (Real-world Example)
Bài toán: Một chuỗi trà sữa Phúc Long muốn dự báo doanh số dựa trên nhiệt độ ngoài trời.
| Tuần | Nhiệt độ (°C) x | Số ly bán (y) |
|---|---|---|
| 1 | 28 | 350 |
| 2 | 32 | 420 |
| 3 | 35 | 480 |
| 4 | 30 | 390 |
| 5 | 33 | 440 |
Sau khi tính toán:
Nghĩa là: Mỗi khi nhiệt độ tăng 1°C, số ly bán tăng thêm 18 ly. Nếu ngày mai dự báo 36°C → Dự báo bán = -150 + 18(36) = 498 ly.
Liên kết (Related Concepts)
Time-Series Methods (Phương pháp chuỗi thời gian)
Định nghĩa (Definition)
Time-Series Methods sử dụng dữ liệu lịch sử của chính biến cần dự báo, giả định rằng mẫu trong quá khứ sẽ tiếp tục trong tương lai.
Giải thích chi tiết (Detailed Explanation)
1. Naive Forecast (Dự báo ngây thơ)
Phương pháp đơn giản nhất: Dự báo kỳ tới = Giá trị thực tế kỳ hiện tại
- Ví dụ: Tháng 3 bán 500 → Dự báo tháng 4 = 500
- Ưu điểm: Cực kỳ đơn giản, chi phí = 0
- Nhược điểm: Không xem xét xu hướng hay mùa vụ
- Dùng làm benchmark để so sánh với phương pháp phức tạp hơn
2. Moving Average (Trung bình trượt)
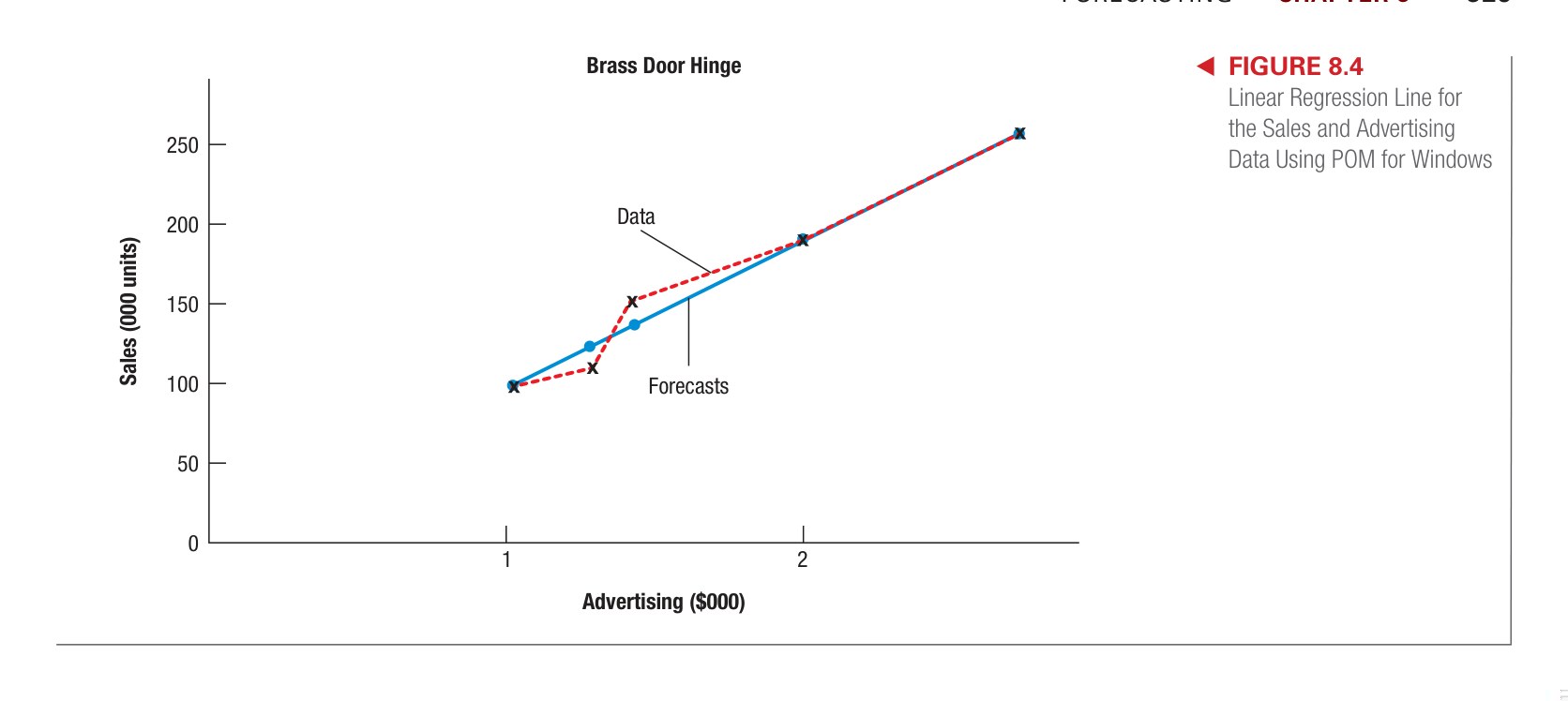
Figure 8.4: Phương pháp trung bình trượt (Moving Average) — so sánh n khác nhau và độ nhạy với dữ liệu
Lấy trung bình của n kỳ gần nhất:
- n lớn → dự báo mượt hơn, phản ứng chậm với thay đổi
- n nhỏ → dự báo nhạy hơn, nhưng nhiều nhiễu
Ví dụ: Doanh số 3 tháng gần nhất: 200, 220, 210
- Simple Moving Average (n=3): F = (200 + 220 + 210)/3 = 210
3. Weighted Moving Average (Trung bình trượt có trọng số)
Trong đó: và thường (kỳ gần hơn có trọng số lớn hơn)
Ví dụ: Doanh số: 200, 220, 210 với trọng số: 0.5, 0.3, 0.2
- F = 0.5(210) + 0.3(220) + 0.2(200) = 105 + 66 + 40 = 211
So sánh với Simple Moving Average = 210. Kỳ gần nhất (210) được tính nặng hơn nên kết quả hơi khác.
4. Exponential Smoothing (San mũ / Làm trơn mũ)
Phương pháp phổ biến nhất trong thực tế! Công thức đệ quy:
Hay viết lại:
Trong đó:
- (Smoothing Constant) = hệ số san,
- cao (gần 1): phản ứng nhanh với thay đổi gần đây → tốt khi nhu cầu biến động
- thấp (gần 0): dự báo ổn định hơn → tốt khi nhu cầu ổn định
- Thường dùng: = 0.1 đến 0.3
Ví dụ chi tiết:
- Dự báo tháng trước: = 200, Thực tế: = 220, = 0.2
- = 0.2(220) + 0.8(200) = 44 + 160 = 204
- Dự báo “kéo lên” 4 đơn vị về phía thực tế (220-200=20, và 20×0.2=4)
Tại sao gọi là “mũ”? Vì khi khai triển công thức: Trọng số giảm theo hàm mũ → dữ liệu cũ có ảnh hưởng giảm dần.
Ví dụ thực tế (Real-world Example)
Shopee dùng Exponential Smoothing để dự báo lượng đơn hàng xử lý mỗi ngày cho trung tâm phân loại. Trước các đợt sale lớn (11/11, 12/12), họ chuyển sang cao hơn để phản ứng nhanh với sự tăng vọt. Sau sale, giảm về bình thường.
Liên kết (Related Concepts)
Trend Patterns: Using Regression (Xu hướng: Sử dụng hồi quy)
Định nghĩa (Definition)
Khi nhu cầu có Trend (xu hướng tăng/giảm dài hạn), các phương pháp cơ bản như Moving Average và Exponential Smoothing đơn giản sẽ luôn đi sau (lag). Cần phương pháp điều chỉnh xu hướng.
Giải thích chi tiết (Detailed Explanation)
Phương pháp 1: Linear Regression cho Trend
- Dùng thời gian (t) làm biến độc lập x
- trong đó t = 1, 2, 3, … (các kỳ thời gian)
Ví dụ: Doanh số qua 5 quý:
| Quý (t) | Doanh số (y) |
|---|---|
| 1 | 100 |
| 2 | 120 |
| 3 | 135 |
| 4 | 155 |
| 5 | 170 |
Sau tính toán: Dự báo quý 6: 187
Phương pháp 2: Trend-Adjusted Exponential Smoothing (Phương pháp Holt)
Sử dụng 2 phương trình:
- Ước lượng mức (Level):
- Ước lượng xu hướng (Trend):
Dự báo: (dự báo p kỳ phía trước)
Trong đó:
- = Smoothing Constant cho level
- = Smoothing Constant cho trend
Liên kết (Related Concepts)
Seasonal Patterns: Using Seasonal Factors (Mẫu mùa vụ: Sử dụng hệ số mùa vụ)
Định nghĩa (Definition)
Seasonal Factors (Hệ số mùa vụ / chỉ số mùa vụ) là các giá trị dùng để điều chỉnh dự báo theo mùa, phản ánh sự khác biệt có hệ thống giữa các kỳ trong năm.
Giải thích chi tiết (Detailed Explanation)

Figure 8.9: Mẫu mùa vụ (Seasonal Patterns) — hệ số mùa vụ điều chỉnh dự báo theo chu kỳ lặp lại
Quy trình tính Seasonal Factors theo phương pháp nhân (Multiplicative Method):
Bước 1: Tính nhu cầu trung bình mỗi mùa trên toàn bộ dữ liệu Bước 2: Tính nhu cầu trung bình chung Bước 3: Hệ số mùa vụ = Trung bình mùa / Trung bình chung
- Hệ số > 1.0: mùa cao điểm (nhu cầu trên trung bình)
- Hệ số < 1.0: mùa thấp điểm (nhu cầu dưới trung bình)
- Tổng các hệ số = số mùa (ví dụ: 4 quý thì tổng = 4.0)
Bước 4: Dự báo = Dự báo trung bình × Hệ số mùa vụ
Ví dụ thực tế (Real-world Example)
Bài toán: Chuỗi khách sạn ở Đà Nẵng dự báo lượng khách cho năm tới.
| Quý | Năm 1 | Năm 2 | Năm 3 | TB mùa | Hệ số mùa |
|---|---|---|---|---|---|
| Q1 (Xuân) | 300 | 320 | 340 | 320 | 320/400 = 0.80 |
| Q2 (Hè) | 550 | 580 | 610 | 580 | 580/400 = 1.45 |
| Q3 (Thu) | 400 | 420 | 380 | 400 | 400/400 = 1.00 |
| Q4 (Đông) | 250 | 280 | 270 | 300 | 300/400 = 0.75 |
Trung bình chung = (320+580+400+300)/4 = 400
Nếu dự báo năm 4 tổng = 1,800 → TB/quý = 450
- Q1: 450 × 0.80 = 360
- Q2: 450 × 1.45 = 652
- Q3: 450 × 1.00 = 450
- Q4: 450 × 0.75 = 338
Kết hợp với Trend: Có thể dùng Linear Regression để dự báo mức trung bình trước, rồi nhân với Seasonal Factors.
Liên kết (Related Concepts)
Big Data and Forecasting (Dữ liệu lớn và Dự báo)
Định nghĩa (Definition)
Big Data trong dự báo là việc sử dụng lượng dữ liệu khổng lồ từ nhiều nguồn (mạng xã hội, IoT, giao dịch, GPS…) kết hợp với Machine Learning và Artificial Intelligence để cải thiện chất lượng dự báo.
Giải thích chi tiết (Detailed Explanation)
Các xu hướng hiện đại:
-
Predictive Analytics: Dùng thuật toán ML để phát hiện mẫu phức tạp mà phương pháp truyền thống bỏ lỡ. Ví dụ: Amazon dự đoán bạn sẽ mua gì trước khi bạn biết mình cần.
-
Social Media Analytics: Phân tích dữ liệu từ Facebook, TikTok, Twitter để cảm nhận xu hướng nhu cầu. Ví dụ: một hashtag viral về matcha → dự báo tăng nhu cầu bột matcha.
-
Internet of Things (IoT): Cảm biến trên kệ hàng tự động báo số lượng tồn kho → dự báo real-time. Ví dụ: máy bán hàng tự động báo về server khi còn 20% hàng.
-
Collaborative Filtering: Dự báo nhu cầu cá nhân dựa trên hành vi người dùng tương tự. Netflix, Spotify dùng phương pháp này.
-
Kết hợp phương pháp (Combination Forecasts): Nghiên cứu cho thấy kết hợp nhiều phương pháp dự báo thường cho kết quả tốt hơn bất kỳ phương pháp đơn lẻ nào.
Ví dụ thực tế (Real-world Example)
Grab Việt Nam sử dụng Big Data từ hàng triệu chuyến xe mỗi ngày, kết hợp dữ liệu thời tiết, sự kiện, lịch lễ, và vị trí GPS để dự báo nhu cầu theo từng khu vực và khung giờ. Điều này giúp họ điều phối tài xế (Driver Allocation) hiệu quả hơn.
Liên kết (Related Concepts)
Công thức quan trọng (Key Formulas)
| Công thức | Ký hiệu | Mô tả |
|---|---|---|
| Forecast Error | Sai số dự báo | |
| CFE | Tổng tích lũy sai số (đo thiên lệch) | |
| MAD | Độ lệch tuyệt đối trung bình | |
| MAPE | Sai số % tuyệt đối trung bình | |
| MSE | Sai số bình phương trung bình | |
| Moving Average | Trung bình trượt n kỳ | |
| Exponential Smoothing | San mũ () | |
| Linear Regression | Hồi quy tuyến tính | |
| Slope | Hệ số góc | |
| Coefficient of Determination | % biến thiên được giải thích |
Từ khóa chính (Key Terms)
- Forecasting - Dự báo
- Demand Patterns - Các mẫu nhu cầu
- Trend - Xu hướng
- Seasonal Pattern - Mẫu mùa vụ
- Cyclical Pattern - Mẫu chu kỳ
- Random Variation - Biến động ngẫu nhiên
- Forecast Error - Sai số dự báo
- CFE - Tổng tích lũy sai số
- MAD - Độ lệch tuyệt đối trung bình
- MAPE - Sai số % tuyệt đối trung bình
- MSE - Sai số bình phương trung bình
- Judgment Methods - Phương pháp định tính
- Delphi Method - Phương pháp Delphi
- Sales Force Estimates - Dự báo từ đội ngũ bán hàng
- Market Research - Nghiên cứu thị trường
- Linear Regression - Hồi quy tuyến tính
- Correlation Coefficient - Hệ số tương quan
- Naive Forecast - Dự báo ngây thơ
- Moving Average - Trung bình trượt
- Weighted Moving Average - Trung bình trượt có trọng số
- Exponential Smoothing - San mũ / Làm trơn mũ
- Smoothing Constant - Hằng số san ()
- Seasonal Factors - Hệ số mùa vụ
- Trend-Adjusted Exponential Smoothing - San mũ có điều chỉnh xu hướng
- Big Data - Dữ liệu lớn
- Predictive Analytics - Phân tích dự đoán
- Time-Series Methods - Phương pháp chuỗi thời gian
- Causal Methods - Phương pháp nhân quả